Dynamic Programming : Policy Iteration & Value Iteration
2018. 11. 9. 23:04
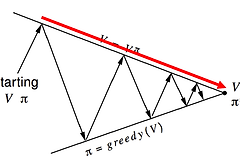
Dynamic Programming : Policy Iteration & Value Iteration 돌아서면 까먹는 미래의 나를 위해....다시 보아도 바로 이해할 수 있도록 정리한다. MDP가 뭐였지? Markov Decision Processes는 Total Reward를 최대로 만들고, 이때의 Optimal Policy를 찾는 방법이었다.MDP에서 중요한 점은 Model을 알고 있다는 점이다.여기서 Model은 Transition Probability, Reward Function을 말하는데, 보통은 Transition Probability를 의미한다. 즉, 모든 상황(Observation)을 다 알고 있다는 의미다. Agent가 지금 state에서 action을 취했을 때, 다음 state의 확..


